Blog
Automating Kubernetes deployments
Let’s move on to automating Kubernetes deployments now, having automated building of Docker images containing latest versions of our applications and pushing them to registry, as described in my most recent article “Painless Monolith breakup or how automation and efficient design enables smooth transitions“.
This is the last article in this series, explaining in more detail the technologies used in the Automated Linguistic Analysis application https://github.com/ideas-into-software/automated-linguistic-analysis; you can clone, configure and deploy the application yourself–all steps are documented.
1. We already have the k8-maven-plugin plugin included in our build and referenced in POMs–for details regarding these steps please see my most recent article “Painless Monolith breakup or how automation and efficient design enables smooth transitions“. Therefore, in the main project POM https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/pom.xml we extract few more properties into variables to be referred to later; we also specify insecure Docker registry, which is required if using Docker local registry with minikube1, i.e.:
<properties>
(…)
<k8-maven.docker-registry>192.168.0.53:5000</k8-maven.docker-registry>
<k8-maven.insecureRegistry>${k8-maven.docker-registry}</k8-maven.insecureRegistry>
<k8-maven.memory>8192</k8-maven.memory>
<k8-maven.cpus>4</k8-maven.cpus>
(…)
</properties>
2. In the same main project POM https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/pom.xml, we add the cluster execution definition, specifying the startMinikube and apply goals to be run as part of the deployment phase: the startMinikube goal will start minikube with insecureRegistry, memory and cpus args as per our definition, while the apply goal will afterwards run kubectl apply -f on any of the Kubernetes descriptors in application modules, which we’ll discuss in a moment, i.e.:
<profile>
<id>k8</id>
<build>
<pluginManagement>
<plugins>
(…)
<plugin>
<groupId>com.github.deanjameseverett</groupId>
<artifactId>k8-maven-plugin</artifactId>
<version>${k8-maven.version}</version>
<executions>
(…)
<execution>
<id>cluster</id>
<phase>deploy</phase>
<goals>
<goal>startMinikube</goal>
<goal>apply</goal>
</goals>
<configuration>
<insecureRegistry>${k8-maven.insecureRegistry}
</insecureRegistry>
<memory>${k8-maven.memory}</memory>
<cpus>${k8-maven.cpus}</cpus>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</pluginManagement>
</build>
</profile>
3. Since by default the maven-deploy-plugin plugin is triggered in deploy Maven lifecycle phase, but we want to deploy to Kubernetes cluster instead, we disable it for this profile, i.e.:
<profile>
<id>k8</id>
<build>
<pluginManagement>
<plugins>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<configuration>
<skip>true</skip>
</configuration>
</plugin>
(…)
</plugins>
</pluginManagement>
</build>
</profile>
4. Now, for each application extracted in steps 1-3 in the previous article “Painless Monolith breakup or how automation and efficient design enables smooth transitions“, having added Docker files to src/main/docker directories, we now add Kubernetes descriptors to src/main/k8 directories. Here, we can also use Maven variables, so instead of hard-coding information we can simply extract it from Maven, thus our descriptors, just like our Docker files, can be re-used unless some special functionality is needed for that particular application, i.e.:
(…)
containers:
- image: @k8-maven.docker-registry@/ala-@project.artifactId@:@project.version@
name: ala-@project.artifactId@
(…)
You can view full descriptor for the k8-transcription-app application at https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/k8-transcription-app/src/main/k8/k8-transcription-app.yaml, for the k8-linguistics-app application at https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/k8-linguistics-app/src/main/k8/k8-linguistics-app.yaml and for the k8-web-app application at https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/k8-web-app/src/main/k8/k8-web-app.yaml.
5. We obviously need infrastructure, in our case a database and a message broker, to be deployed before our applications are deployed. Having Kubernetes descriptor files, we can also automate applying them via the same k8-maven-plugin plugin. For this particular set up, I use 2 instances of RabbitMQ https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/k8-infra/src/main/k8/infra-rabbitmq-statefulset.yaml and 2 instances of CockroachDB https://github.com/ideas-into-software/automated-linguistic-analysis/blob/master/k8-infra/src/main/k8/infra-cockroachdb-statefulset.yaml, both as StatefulSets2; those I adopted from RabbitMQ’s3 and CockroachDB’s4 public repositories. We then apply them during deploy phase having defined them in k8-infra module’s POM file, i.e.
<profiles>
<profile>
<id>k8</id>
<build>
<plugins>
<plugin>
<groupId>com.github.deanjameseverett</groupId>
<artifactId>k8-maven-plugin</artifactId>
<executions>
<execution>
<id>cluster</id>
<configuration>
<includeFiles>
<!-- Set up RabbitMQ -->
<param>infra-rabbitmq-statefulset.yaml</param>
<!-- Set up CockroachDB -->
<param>infra-cockroachdb-statefulset.yaml</param>
<param>infra-cockroachdb-cluster-init.yaml</param>
</includeFiles>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
</profiles>
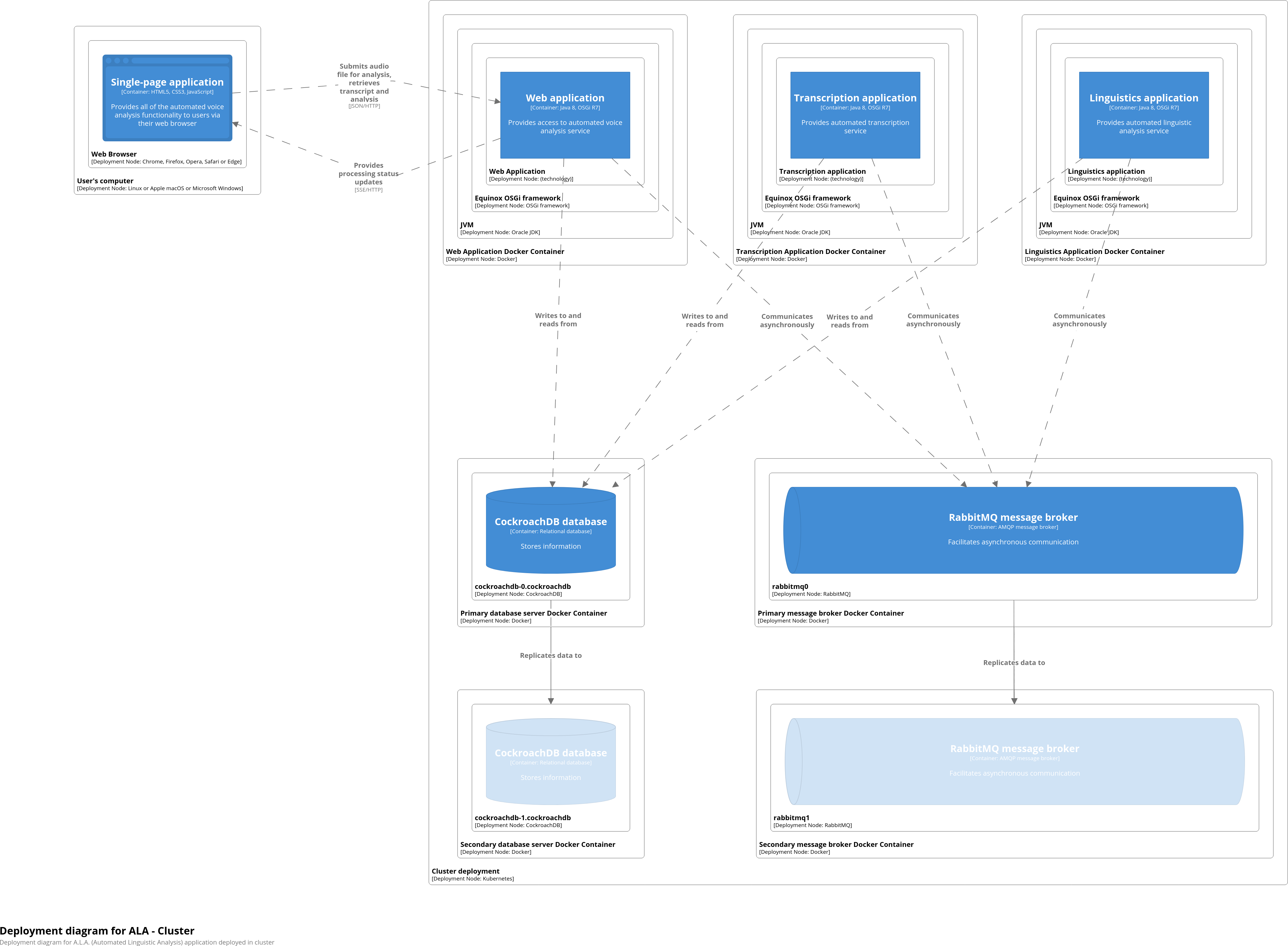
6. We can now deploy both infrastructure and applications onto Kubernetes cluster with one simple command:
mvn -P k8 deploy
This will automatically generate the following:
-
”minikube” https://github.com/kubernetes/minikube ↩
-
”StatefulSets” https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/ ↩
-
“Deploy RabbitMQ on Kubernetes with the Kubernetes Peer Discovery Plugin” https://github.com/rabbitmq/rabbitmq-peer-discovery-k8s/tree/master/examples/k8s_statefulsets ↩
-
“CockroachDB on Kubernetes as a StatefulSet” https://github.com/cockroachdb/cockroach/tree/fcc1637698fd0ec91c181bd096f963d35a16e4e8/cloud/kubernetes ↩